Transformer-Based Radiotherapy Dose Prediction
Summary
In radiotherapy, clinicians need to plan exactly how much radiation to deliver to a tumor while minimizing damage to surrounding healthy organs. This planning is time-consuming and requires deep expertise. This project uses deep learning to predict optimal radiation dose distributions for head and neck cancer patients.
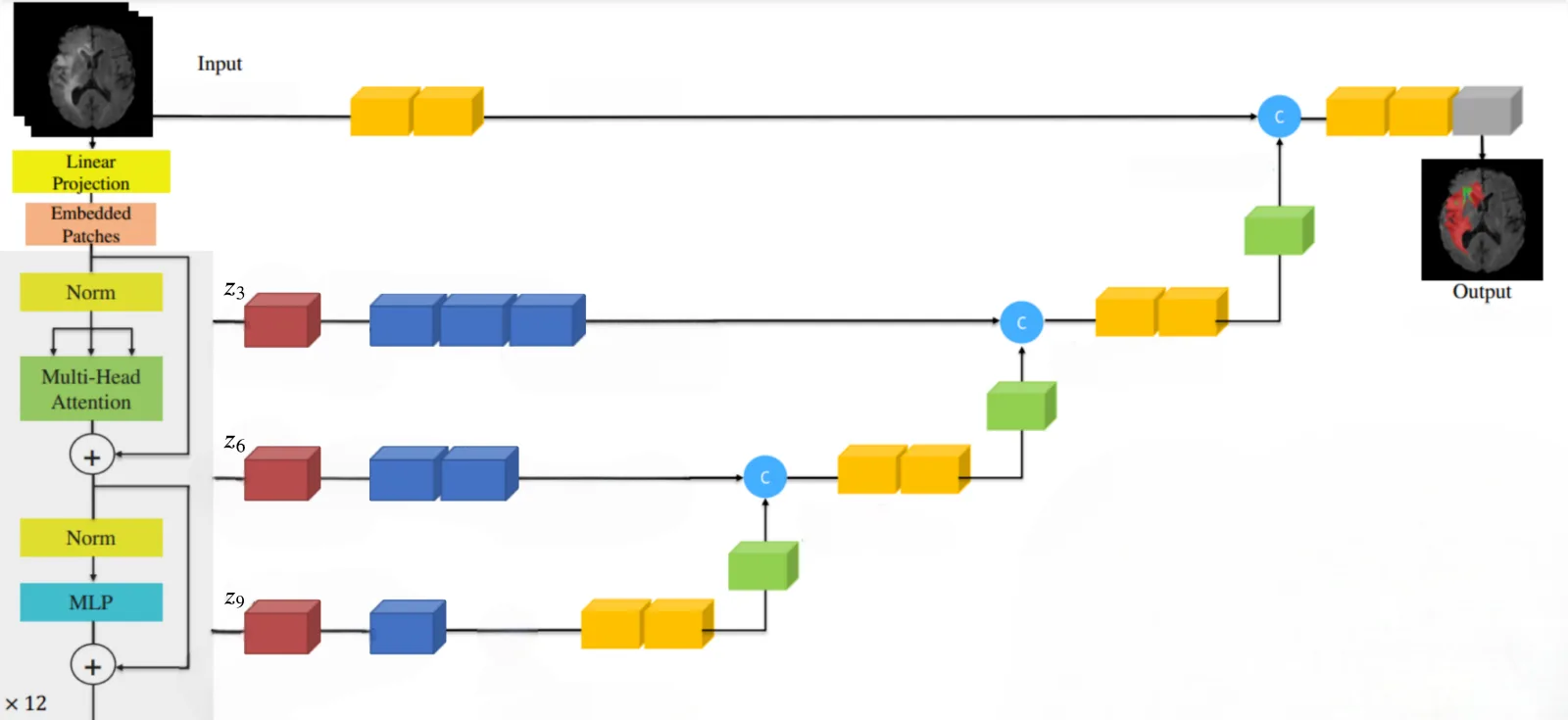
We attempted to reproduce a recent transformer-based approach (TrDosePred), but found the original paper lacked sufficient implementation details. Instead, we built on UNETR, a hybrid architecture combining a Vision Transformer (which captures global context in 3D scans) with a U-Net decoder (which produces fine-grained spatial predictions). We then extended it with physics-informed training objectives and a novel sequential prediction strategy that significantly improved results.
Key Contributions
- Reproduction study documenting the real-world challenges of reproducing ML papers that omit key implementation details.
- Physics-informed training objectives. Instead of only minimizing pixel-level error, we added two clinically motivated losses: a DVH loss that penalizes deviations from ideal dose-volume histograms (the charts clinicians use to evaluate treatment plans), and a Moment loss that matches the statistical properties of dose distributions within each organ.
- Sequential slice prediction with RNN. Rather than predicting the entire 3D dose volume at once, a recurrent neural network predicts one slice at a time while remembering context from previous slices. This was the key improvement, and unlike input masking (which re-runs the model per slice and was 10-20x slower), the RNN added no computational overhead.
Method
The model takes as input a 3D CT scan of a patient's head and neck (128×128×128 voxels), along with masks indicating where the tumor and critical organs are located. It outputs a predicted radiation dose for every point in the volume. We used data from the OpenKBP Challenge, which includes scans from 340 patients.
The architecture is UNETR: a Vision Transformer processes the full 3D scan to capture long-range spatial relationships (e.g., how the tumor's position relates to distant organs), while a U-Net-style decoder generates the detailed voxel-by-voxel dose prediction. We tested 9-block and 12-block encoder variants.
On top of the standard pixel-wise error (MAE), we explored two physics-informed losses. DVH loss directly optimizes the dose-volume histograms that clinicians review when evaluating plans. Moment loss ensures the predicted dose has the right statistical shape within each organ structure.
For sequential prediction, we compared three strategies. The winning approach uses a convolutional RNN that processes the 3D volume slice-by-slice, building up a running memory of what it has predicted so far, similar to how a human might plan treatment one cross-section at a time.
Results
| Configuration | DVH Score ↓ | Dose Score ↓ |
|---|---|---|
| TrDosePred (original paper) | 2.512 | 1.658 |
| UNETR 9-block (MAE baseline) | 4.252 | 5.587 |
| UNETR 12-block | 4.081 | 6.405 |
| MAE + DVH loss | 4.777 | 5.730 |
| MAE + Moment loss | 4.233 | 5.706 |
| MAE + RNN autoregression | 3.811 | 4.927 |
Both scores measure prediction error (lower is better). DVH Score reflects clinical plan quality; Dose Score measures voxel-level accuracy. The RNN-based sequential decoder improved both metrics ~10% over the baseline with no additional computational cost. Physics-based losses alone gave marginal improvement, likely needing more tuning. While the original TrDosePred results could not be reproduced, the UNETR + RNN extension narrows the gap substantially.