Injecting Image Guidance into Diffusion Models
Summary
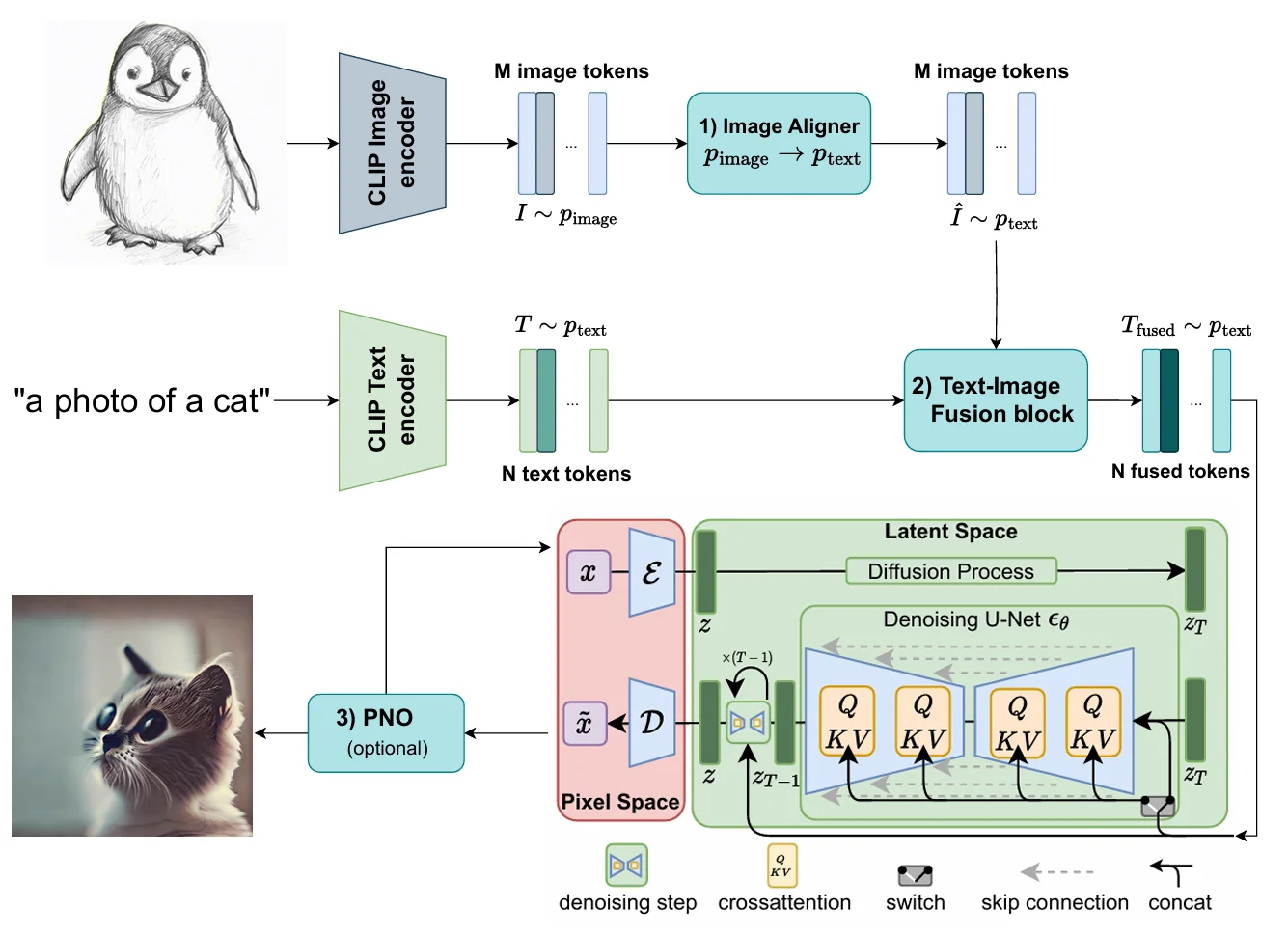
Visual Concept Fusion (VCF) enables dual conditioning of Stable Diffusion on both a text prompt and a reference image at inference time, without retraining the model. It trains a lightweight aligner network (a 2-layer MLP) that translates CLIP image embeddings into the CLIP text embedding space, allowing the frozen diffusion model to process visual and textual guidance together.
An optional Prompt-Noise Optimization (PNO) step refines the generation at test time by iteratively adjusting the conditioning and initial noise to maximize visual similarity to the reference. The result is generated images that respect the text prompt while inheriting style, color palette, composition, and texture from the reference image.
Key Contributions
- No diffusion model fine-tuning required. The core Stable Diffusion model stays frozen; only a small aligner network is trained (under 2 hours on a single A100 GPU, using just 10% of the COCO Captions dataset).
- Novel combined training objective. The aligner is trained with two complementary losses: InfoNCE, a contrastive loss that learns to match image-text pairs globally, and a cross-attention reconstruction loss that preserves fine-grained token-level structure. Together they bridge the gap between how CLIP represents images versus text.
- Three fusion strategies explored. Simple averaging, concatenation, and cross-attention fusion are compared; concatenation (appending image features alongside text features) yields the best balance of prompt fidelity and reference adherence.
- Prompt-Noise Optimization (PNO). A test-time refinement loop that iteratively adjusts the generation starting point to make the output more visually similar to the reference image.
Method
The pipeline consists of three components. First, an Image Aligner, a small two-layer network that translates CLIP image features into the same representation space as CLIP text features. It is trained with a combined objective: a contrastive loss (InfoNCE) for global alignment and a cross-attention loss for preserving local detail.
Second, Text-Image Fusion appends the translated image features alongside the text features, so the diffusion model receives both as a single combined input. This preserves both modalities without destructive blending.
Third, optional Prompt-Noise Optimization runs 10-50 optimization steps at test time, adjusting both the combined input and the initial random noise to push the generated image closer to the reference. The base model is Stable Diffusion v2.1 at 768×768 resolution with DDIM sampling (50 steps).
Results
| Method | CLIP Score ↑ | LPIPS (perceptual distance) ↓ |
|---|---|---|
| SD v2 (text-only) | 0.29 | 0.78 |
| Naive fusion | 0.28 | 0.77 |
| VCF (Ours) | 0.27 | 0.76 |
CLIP Score measures how well the generated image matches the text prompt; LPIPS measures perceptual distance to the reference image (lower means more similar). VCF achieves the best visual similarity to reference images while only slightly reducing text alignment. PNO consistently improves both structural alignment and color fidelity. The method transfers high-level qualities (artistic style, background elements) and low-level details (color palette, shading) from reference images.